 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|||||||||
| PREV PACKAGE NEXT PACKAGE | FRAMES NO FRAMES | ||||||||
| Interface Summary | |
|---|---|
| AdaptiveStrategy | Strategies implementing this interface indicate that they are based on a learning algorithm. |
| FixedQuantityStrategy | Strategies implementing this interface indicate that they bid a constant quantity in each market round. |
| TradeDirectionPolicy | Classes defining this interface are responsible for deciding which direction --- long or short --- should be taken by the specified TradingAgent. |
| Class Summary | |
|---|---|
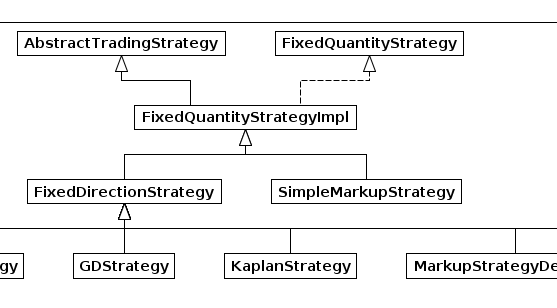
| AbstractTradingStrategy | An abstract implementation of the Strategy interface that provides skeleton functionality for making trading decisions. |
| AdaptiveStrategyImpl | |
| BeatTheQuoteStrategy | |
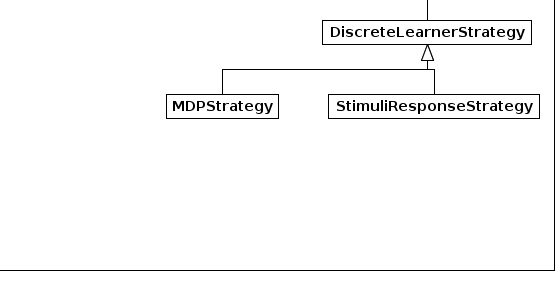
| DiscreteLearnerStrategy | A class representing a strategy in which we adapt our bids using a discrete learning algorithm. |
| EquilibriumPriceStrategy | A strategy which will bid at the true equilibrium price, if profitable, or bid truthfully otherwise. |
| EstimatedEPStrategy | |
| FixedDirectionStrategy | |
| FixedPriceStrategy | |
| FixedQuantityStrategyImpl | An abstract implementation of FixedQuantityStrategy. |
| FixedTradeDirectionPolicy | A trade direction policy which specifies a configurable fixed position to take in the market. |
| ForecastTradeDirectionPolicy | Decide whether to long or short based on whether the agents' valuation for the asset is greater than the current price. |
| GDLStrategy | A modified implementation of the Gjerstad Dickhaut strategy. |
| GDQStrategy | An implementation of the modified Gjerstad Dickhaut strategy in which quadratic, instead of cubic originally, functions are used to calculate the probability of any bid being accepted and bid to maximize expected profit. |
| GDStrategy | An implementation of the Gjerstad Dickhaut strategy. |
| KaplanStrategy | An implementation of Todd Kaplan's sniping strategy. |
| MarkupStrategyDecorator | This strategy decorates a component strategy by bidding a fixed proportional markup over the price specified by the underlying component strategy. |
| MDPStrategy | A trading strategy that uses an MDP learning algorithm, such as the Q-learning algorithm, to adapt its trading behaviour in successive market rounds. |
| MomentumStrategy | |
| PriestVanTolStrategy | |
| ProportionalMarkupStrategy | This strategy bids at the specified percentage markup over the agent's current valuation. |
| PureSimpleStrategy | A trading strategy in which we bid a constant mark-up on the agent's private value. |
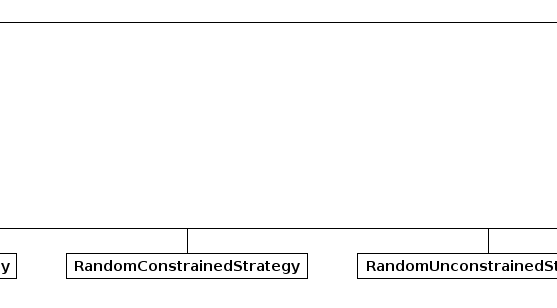
| RandomConstrainedStrategy | A trading strategy that in which we bid a different random markup on our agent's private value in each market round. |
| RandomUnconstrainedStrategy | A trading strategy in which an agent bid regardless its private value. |
| SimpleMarkupStrategy | A strategy which sets the current price and direction of the agent's order based on a forecast of the next period price, as specified by the agent's valuation policy. |
| SimpleMomentumStrategy | |
| StimuliResponseStrategy | A trading strategy that uses a stimuli-response learning algorithm, such as the Roth-Erev algorithm, to adapt its trading behaviour in successive market rounds by using the agent's profits in the last round as a reward signal. |
| TruthTellingStrategy | |
| ZIPStrategy | An implementation of the Zero-Intelligence-Plus (ZIP) strategy. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
| PREV PACKAGE NEXT PACKAGE | FRAMES NO FRAMES | ||||||||